
Learning (Training) 학습
훈련 데이터(training set)로부터 가중치 매개변수의 최적(optimization) 값을 자동으로 획득하는 것
Learning의 최종 목표 : 내가 어떤 신경망을 디자인했다면, 그 신경망의 최적의 가중치를 찾아내는 것
End-to-End Machine Learning 종단간 기계학습
데이터(입력)에서 목표한 결과(출력)를 사람의 개입 없이 얻으므로 딥러닝을 종단간 기계 학습이라 부르기도 한다.
Q. 신경망의 성능을 평가하기 위해 신경망을 구성하는데, 이때 신경망을 구성한다는 것은 무슨 뜻일까?
A. 가중치와 매개변수를 찾겠다는 것
Training Data 훈련 데이터 & Test Data 시험 데이터
- 훈련 데이터 : 최적의 가중치 매개변수 탐색 (신경망의 가중치를 찾기 위해 학습하는 것)
- 시험 데이터 : 훈련한 모델의 성능 평가 (test set으로는 찾아낸 신경망의 성능을 평가)
test set으로는 training하지 않는다. - 소요시간 : training set > test set
- 학습을 시킨 후 가중치를 뽑아내서 그 가중치를 그대로 가지고 있는 신경망을 가지고 test set으로 돌리는 것.
-> 내가 찾아낸 신경망의 성능이 어떻게 되는지는 test set으로 확인한다.
Underfitting 과소 적합 vs. Overfitting 과대 적합
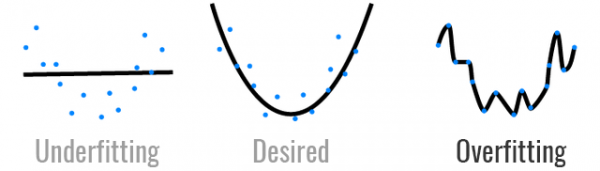
- Underfitting : typical learning curve for high bias (편향이 크다)
- bias란, prediction 다 한 다음에, 모델의 training data가 얼마나 근접하게 가까이 모여 있는지를 나타내는 것
- prediction 한 데이터가 한쪽으로 쏠려있다. e.g. 개랑 고양이를 나누는 데이터가 있는데 100개 중 99개가 🐶이다.
-> test set 자체가 한쪽으로 편향이 되어 있다. 편향이 되어 있는 상태에서는 고양이(test set)가 들어올 경우 성능이 확 떨어진다. 고양이가 들어와도 training 된 set이 없기 때문에 개라고 생각. - 즉, training set, test set 둘 다 성능이 떨어진다. 너무 단순하게 피팅시킴
- Overfitting : typical learning curve for high variance (변이가 크다)
- 모델이 training set A에서는 결과(모델의 성능)가 99%가 나오고 training set B에서는 60%가 나올 경우 변이가 크다고 한다. 즉, 내가 어떤 data set이 들어오느냐에 따라 너무 모델이 그 데이타셋에 맞춰져 만들어졌기 때문에 결과의 차이가 크게 나온다. -> high variance
- 따라서 test set에 비해 training set 성능만 너무 뛰어날 경우 overfitting이라 한다. training set에만 너무 최적화된 데이터를 심으면 패턴이 다른 test set이 들어왔을 때 성능이 떨어질 수밖에 없다.
Loss function 손실 함수
- 신경망 성능의 ‘나쁨’을 나타내는 지표
- 신경망이 훈련 데이터를 얼마나 잘 처리하지 못하느냐를 나타냄
- 즉, 손실 함수는 신경망이 학습이 잘되고 있는지 그렇지 못한 지의 기준이 된다.
- 평균 제곱 오차와 교차 엔트로피 오차를 가장 많이 사용한다.
Mean squared error (MSE, 평균 제곱 오차)

yk : 신경망의 출력 (신경망이 추정한 값) - 예측값
tk : 정답 레이블 - 정답 값
k : 데이터의 차원 수 - 클래스 수 (분류하고자 하는 데이터 수)
정답을 맞히면 값이 작아진다. 정답을 다 맞히면 0이 나온다.
손실 함수는 작아질수록 좋다. 그러나 정답만 맞히도록 학습시키면 안 된다 -> 오버 피팅
One-hot encoding (원-핫 인코딩)
데이터를 쉽게 중복 없이 표현할 때 사용하는 형식
- 각 단어에 고유한 인덱스 부여
- 표현하고 싶은 단어의 인덱스 위치에 1을 부여, 다른 단어의 인덱스 위치에는 0을 부여
e.g. 사과[1,0,0] 오렌지[0,1,0] 포도[0,0,1]
단점
- 데이터가 많을 경우 size가 급격히 증가함 (클래스가 많으면 메모리를 많이 차지한다. 60000개 중 사과 하나만 1)
- 벡터가 sparse 할 확률이 높음 (정보가 없는 데이터가 많아짐)
Cross entropy error (CEE, 교차 엔트로피 오차)

yk : 신경망의 출력 (신경망이 추정한 값) - 예측값
tk : 정답 레이블 - 정답 값
k : 데이터의 차원 수 - 클래스 수 (분류하고자 하는 데이터 수)
log로 곱한다. 정답은 벡터로 표현하는데 정답이면 1, 정답이 아니면 0이다.
0이 되면 정답을 계산할 필요가 없다. 즉, tk의 값이 1을 가질 때만 계산한다.
분류하고자 하는 데이터 수가 많을 경우, loss function 계산할 것이 많아지므로 미니 배치를 구성한다.
e.g. 데이터 수가 60000개 라면, 미니 배치를 구성한다.
Mini-batch 미니 배치
- 훈련 데이터로부터 일부만 골라 학습을 수행.
모든 데이터를 대상으로 손실 함수의 합을 구할 때, 많은 시간이 소모되므로(High computation time) - 미니 배치 학습 : MNIST 데이터셋의 훈련 데이터 60,000개 중 100 장을 무작위로 뽑아 그 100장만 사용하여 학습함
Q. 왜 정확도로 판단하지 않고 손실 함수로 판단하는가?
A. 손실 함수를 지표로 삼는 이유는 정확도를 지표로 삼으면 정확도를 올리더라도 불연속으로 변하기 때문이다. e.g. 100장의 훈련 데이터 중 32장을 맞춘 신경망이 있다고 한다면, 가중치를 변경해 정확도를 높이더라도 34%, 35% 등 불연속적으로 변함. 손실 함수의 경우 매개변수의 작은 변화가 주는 파장을 잡을 수 있다.
Partial Differentiation (편미분)
- 변수가 여럿인 함수에 대한 미분
- 특정 장소의 기울기
미분을 한다는 것 = 접점에서의 기울기를 나타내는 것 = 변화를 나타냄
내가 찾고자 하는 매개 변수가 w 뿐만 아니라 b도 있다고 하면, 변수가 두 개일 때 미분을 편미분이라 한다. f(w, b)

U = 손실 함수를 나타낼 수 있는 값의 범위
f(w)를 미분을 해서 가장 0에 가까운 값을 찾아내는 것이 최적화된 매개변수이다.
손실 함수가 최적이 되는 위치를 local optimum이라 한다. 지역적으로 최적화되는 것을 찾았으므로 local (o) global (x)
global optimum은 시간이 오래 걸려서 사용 못함.
Gradient descent method
"기울기가 낮아지는 쪽으로 찾아가겠다."
- 최적화의 함수에서는 기울기를 사용한다.
- 최적의 매개변수(가중치와 편향)를 학습 시 찾아야 함
- 최적 (Optimization) : 손실 함수가 최솟값이 될 때의 매개변수 값
Learning rate (학습률)
- 갱신의 양, 매개변수 값을 얼마나 갱신하느냐를 정하는 것
- 너무 크면, 큰 값으로 발산하거나 Oscillation을 수행하며 수렴되지 않음
학습률이 높으면 한 번에 여러 개를 넘어갈 수 있어서 좋으나 너무 크게 되면 뛰어넘어가 버림. - 너무 작으면, 거의 갱신되지 않은 채 수렴이 끝남
Hyperparameter (하이퍼파라미터)
- 사람이 직접 설정해야 하는 매개변수
⚠️ 컴퓨터가 찾는 값 = 매개변수, 내가 주는 값 = 하이퍼파라미터 (개념 구분하기) - 학습률은 실험적으로 반복을 통해 찾아냄
신경망 학습 절차
- 1단계: 미니 배치
- 훈련 데이터 중일 부를 무작위로 가져옴. 선별한 데이터(미니 배치)의 손실함수 값을 줄이는 것이 목표임
- 훈련 데이터가 많으면 손실 함수를 계산하는데 시간이 많이 걸리므로 손실 함수를 계산하는 양을 줄이기 위해 미니 배치 구성
- 손실함수를 계산하려면 신경망에서 예측값과 정답 값을 알고 있어야 한다.
- 2단계: 기울기 산출
- 미니 배치의 손실 함숫값을 줄이기 위해 각 가중치 매개변수의 기울기를 구함
- 기울기는 손실 함수의 값을 가장 작게 하는 방향으로 제시함
- 3단계: 매개변수 갱신
- 가중치 매개변수를 기울기 방향으로 조금씩 갱신함 (기울기의 정도는 학습률을 가지고 한다)
- 4단계: 반복
- 1~3단계를 반복함 (미니 배치로만 한다고 하면 2,3단계만 반복)
Stochastic gradient descent (SGD 확률적 경사 하강법)
데이터를 미니 배치로 무작위 선정하여 gradient descent method로 매개변수를 갱신하는 방법
전체 데이터가 아닌 미니 배치로만 최적화를 시키는 것이므로 Stochastic.
Epoch
- 반복 횟수를 의미
- 1 Epoch: 학습에서 훈련 데이터를 모두 소진했을 때의 횟수
내 데이터를 한 번이 아닌 다 돌렸을 때를 1 Epoch라 한다. e.g. 10,000개를 100개의 미니 배치로 학습할 경우, SGD를 100회 반복하면 모든 훈련 데이터를 소진한 게 되므로 100회가 1 epoch 이 됨
정리
- 기계학습에서 사용하는 데이터셋은 훈련 데이터와 시험 데이터로 나눠 사용한다
- 훈련 데이터로 학습한 모델의 범용 능력을 시험 데이터로 평가한다
- 신경망 학습은 손실 함수를 지표로, 손실 함수의 값이 작아지는 방향으로 가중치 매개 변수를 갱신한다.
- 손실 함수를 왜 제시 하였는가?
- 미니배치를 구성하는 이유는?
- 손실 함수를 미분을 해서 기울기가 작아지는 쪽으로 계산한다. -> Gradient descent method
- 기울기가 작아지는 쪽으로 계속 매개변수를 찾아나가는데, 앞에 학습률을 적절하게 찾아줘야 한다.
- 이렇게 직접 찾아줘야 하는 매개변수를 Hyperparameter라 한다.
- 가중치 매개변수를 갱신할 때는 가중치 매개변수의 기울 기를 이용하고, 기울어진 방향으로 가중치의 값을 갱신하는 작업을 반복한다. 이 과정을 최적화라고 한다.
참조 - 사이토 고키(2019). 밑바닥부터 시작하는 딥러닝. 서울: 한빛미디어.
'공부 > 딥러닝 (Tensorflow)' 카테고리의 다른 글
| 오차역전파법 (0) | 2019.10.13 |
|---|---|
| 신경망 Neural Network - 계단 함수, 시그모이드 함수, ReLU 함수 (0) | 2019.10.06 |
| 퍼셉트론 perceptron (0) | 2019.09.26 |
| 머신러닝 (Machine Learning ) (0) | 2019.09.19 |
| 인공지능, 머신러닝, 딥러닝의 차이 (0) | 2019.09.19 |


